
- By
- September 24, 2025
Most of the audience comes up with the same question about how search engine works. A search engine is a tool that searches the Web for websites relevant to real-time queries entered by users. Depending on the search string, search engines return results that are called search engine results pages (SERPs). Usually, the engines get it right and display the most relevant results.
Search engines use no fixed rules to display accurate results. Spiders or crawlers are bots that search for and index website content. The most popular search engines are Google, Yahoo!, and Bing. How does a Search engine work? Search engines determine the most relevant web pages because companies have developed algorithms for the search process. Nowadays, quality link building, fresh and intuitive content, and streamlined navigation are the core factors that determine which websites are on priority at the top of the search results.

There are other factors such as the website’s popularity, the relevance of the content, and the interactive media. Although the exact logic used to obtain results is a business secret. SEO is moving toward a user experience (UX) paradigm, and search engines are constantly evolving and getting smarter by the day.
With its highly accurate results, Google is currently the most sought-after search engine. And is preferred by the vast majority of users, compared to Bing and Yahoo! Google’s innovative search capabilities and market penetration make it the leader in the search engine industry.
(Note that it is impossible to determine exact results because search-engine evolution, innovation, user perception, and protocols change every day. Thus, these statistics are approximate.) You can filter the results based on browser, operating system, and device type.
Modern search engines perform the following processes:
This section presents an overview of each of these before you move on to understanding how a search engine operates.
Web crawlers or web spiders are internet robots that help search engines update their content or index of the web content of various websites. They visit websites on a list of URLs (also called seeds) and copy all the hyperlinks on those sites. Due to the vast amount of content available on the Web, crawlers do not usually scan everything on a web page; rather, they download portions of web pages and usually target pages that are popular, relevant, and have quality links. Some spiders normalize the URLs and store them in a predefined format to avoid duplicate content.
Because SEO prioritizes content that is fresh and updated frequently, some crawlers visit pages where content is updated on a regular basis. Other crawlers are defined such that they revisit all pages regardless of changes in content. It depends on the way the algorithms are written. If a crawler is archiving websites, it preserves web pages as snapshots or cached copies. Crawlers identify themselves as web servers.
This identification process is required, and website administrators can provide complete or limited access by defining a robots.txt file that educates the webserver about pages that can be indexed as well as pages that should not be accessed.
For example, a website’s home page may be accessible for indexing, but pages involved in transactions—such as payment gateway pages—are not because they contain sensitive information. Checkout pages are not indexed because they do not contain relevant keyword or phrase content other than category/ product pages.
If a server receives continuous requests, it can get caught in a spider trap. In that case, the administrators can tell the crawler’s parents to stop the loops. Administrators can also estimate which web pages are being indexed and streamline those web pages’ SEO properties.

Google Bot (used by Google), Bing Bot (used by Bing and Yahoo!), and Sphinx (an open-source, free search crawler written in C++) are some of the popular crawlers indexing the web for their respective search engines below Image show the basic functional flow of a web crawler.
Indexing methodologies vary from engine to engine. Search-engine owners do not disclose what types of algorithms are used to facilitate information retrieval using indexing. Usually, sorting is done by using forward and inverted indexes. Forward indexing involves storing a list of words for each document, following an asynchronous system-processing methodology. A forward index is a list of web pages and which words appear on those web pages.
On the other hand, inverted indexing involves locating documents that contain the words in a user query; an inverted index is a list of words and which web pages those words appear on. Forward and inverted indexing are used for different purposes.

For example, in forwarding indexing, search engine spiders crawl the Web and build a list of web pages and the words that appear on each page. But in inverted indexing, a user enters a query, and the search engine identifies web pages linked to the words in the query. During indexing, search engines find web pages and collect, parse, and store data so that users can retrieve information quickly and effectively. Imagine a search engine searching the complete content of every web page without indexing—given the huge volume of data on the Web, even a simple search would take hours. Indexes help reduce the time significantly; you can retrieve information in milliseconds.
Forward indexing and inverted indexing are also used in conjunction. During forward indexing, you can store all the words in a document. This leads to asynchronous processing and hence avoids bottlenecks (which are an issue in inverted indexes). Then you can create an inverted index by sorting the words in the forward index to streamline the full-text search process. Information such as tags, attributes, and image alt attributes are stored during indexing. Different media types such as graphics and video can be searchable, depending on the algorithms written for indexing purposes.
A user enters a relevant word or a string of words to get information. You can use plain text to start the retrieval process. What the user enters in the search box is called a search query. This section examines the common types of search queries: navigation, informational, and transactional.
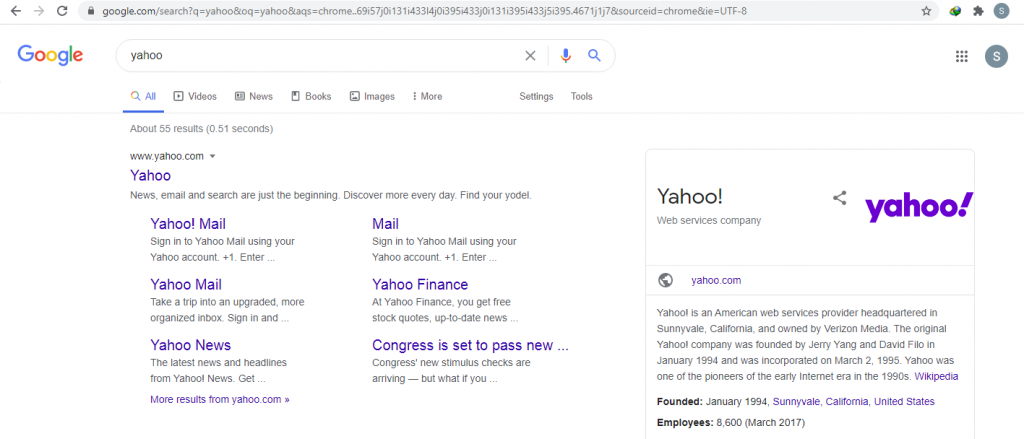
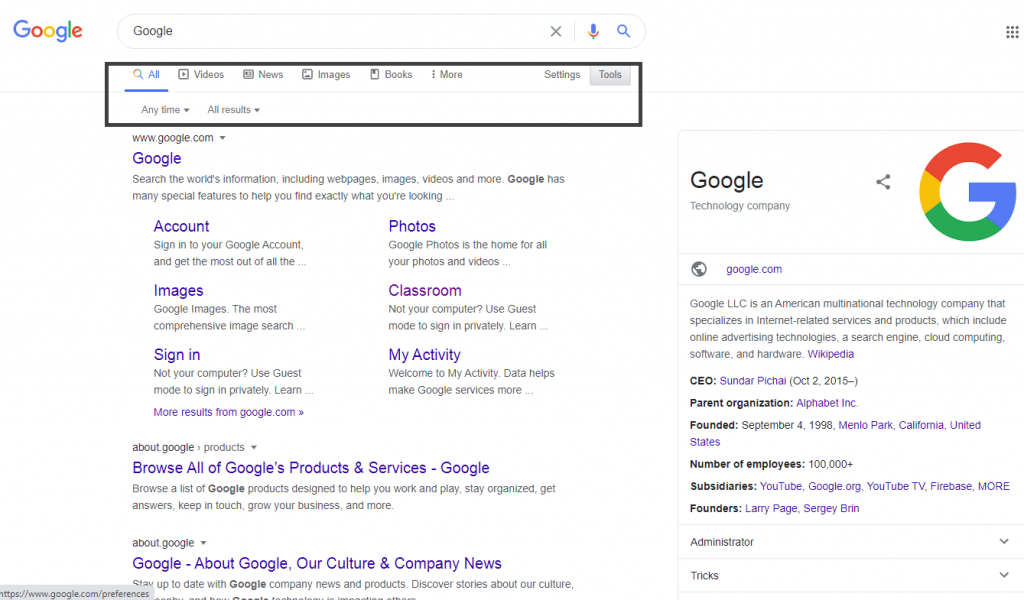
These types of queries have predetermined results because users already know the website they want to access. The image below shows an example: the user has typed Yahoo in the search box and wants to access the Yahoo! website. Because the user already knows the destination to be accessed, this falls under a navigational query heading.
Informational search queries involve finding information about a broad topic and are more generic in nature. Users generally type in real-time words to research or expand their knowledge about a topic.
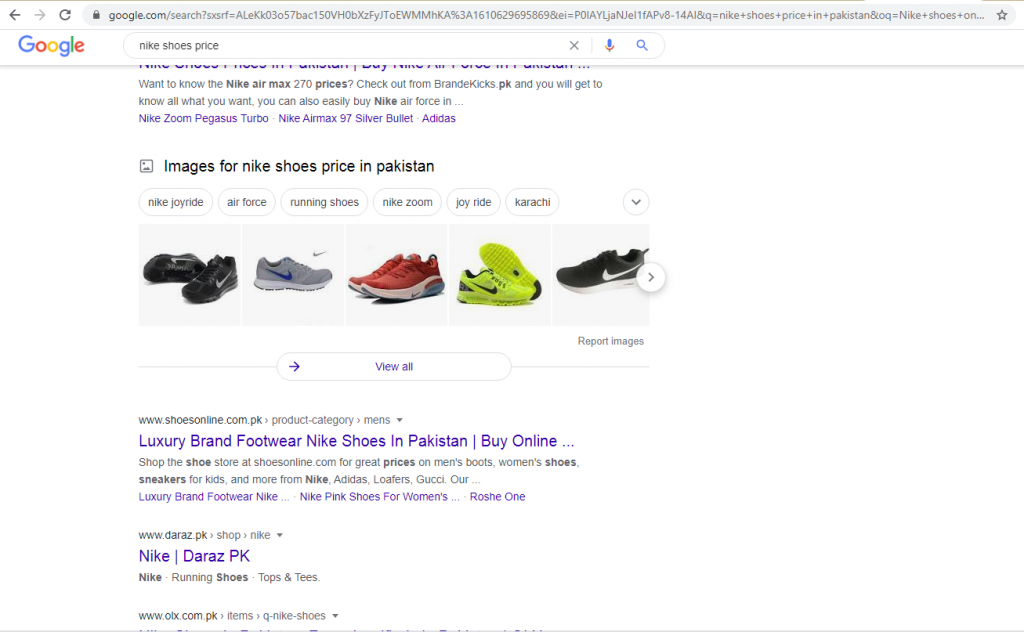
In this type of query, the user’s intent is focused on a transaction, which may be generic or specific. The image below shows the user who wants to check Nike shoes’ prices on online shopping portals (this example uses Google as the search engine). The user knows the brand of shoes they want to buy, and in this case, the search is related to making a purchase. However, not all transactional search queries are purchase-based; they can also involve the user wanting to take some action, such as signing up for a portal.
The previous sections looked at the components and processes related to search engines. This section puts the pieces together so that you understand how a search engine works. A search engine spider visits a website and accesses the robots.txt file to learn which pages of the site are accessible. On gaining access, it sends information about the content to be indexed: this may be hypertext, headings, or title tags, depending on the markup and page content.
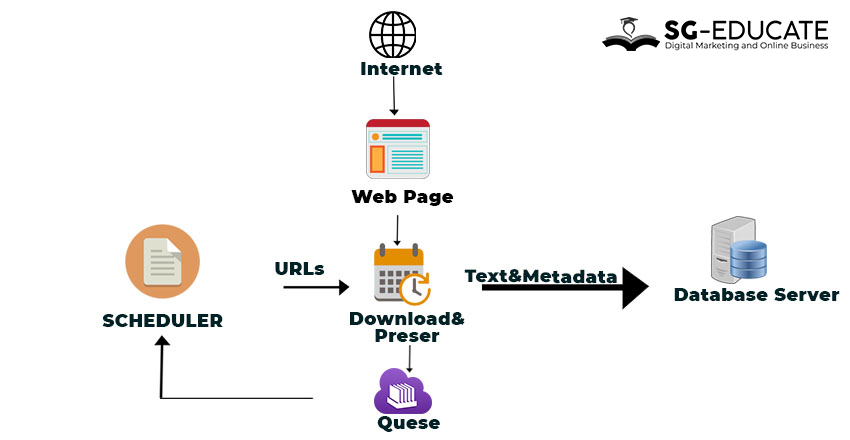
The spider or bot then turns the information into an index: a list of terms and the web pages containing those terms. Web crawlers are constantly updating their index as they search for fresh information. The image below shows the functional flow of bots or spiders accessing web pages and then creating and storing indexes and relevant data on the database server.
When users enter real-time words in a search box to retrieve information, the index containing those terms and their associated websites is accessed. Algorithms (lengthy mathematical equations) configured for ranking the results come into play, and accurate results are displayed on search engine result pages (SERPs). The algorithms determine which sites are ranked higher by assigning values to web pages depending on various factors: fresh, engaging content; localization; metadata; semantics; and fonts displaying prominence, to name a few.
With search engines getting smarter by the day, the algorithms keep changing and evolving to deliver accurate results in a matter of milliseconds. The image below shows how a search query ends up in SERPs.

Searches can also use filters. You can customize a search by using filters that help you get the most relevant information. You can also classify results by using filters according to the categories, or media type’s image below shows category filters such as News, Images, and Maps that help users search by media type.
Also, search filters such as Date and Time filter results further. By being more specific, you can obtain meaningful results and do content-based or concept-based searching.
Not every site is highly ranked in search results due to heavy volume and competition on the Web. Your site may not rank as high if your advertising budget is small compared to heavyweights. Local websites are also becoming difficult to achieve higher rankings because most sites are optimized to gain maximum visibility. Besides, most users use Google, Yahoo!, or Bing (or, in China, Baidu), and not every site can compete with its rivals to rank higher in those engines’ search results, given the limited options.
You need to gauge the alternatives to gain better visibility and increase accessibility to your site. Before creating search engines, web directories were the de facto medium for businesses to reach out to the masses. A web directory contains a collection of links to websites arranged alphabetically or categorized by niche. For example, a plumbing business website appears in the Plumbing category if such a category exists. Most web directories are manually edited, meaning humans sort and enter links based on the categories. Links to your site work as backlinks and help streamline the site’s accessibility to crawlers.
For example, DMOZ is a comprehensive, human-edited web directory maintained by voluntary editors and reviewers. It is the default, widely used web catalog. Some web directories are free, whereas others are commercial—best of the Web Directory.
A listing in a popular online directory increases your site’s visibility significantly, thereby helping you garner more traffic. With high-quality links and an increase in reliable, relevant traffic, your website may receive a fair amount of exposure. Moreover, by appearing in an optimal online directory, your website reflects credibility, which is a boon for brick-and-mortar businesses.

This chapter ( How Search Engine Works) explored the various components involved in search engines and gave you a basic idea of their functionality. You looked at various types of queries and learned about web directories. In addition to Google, Yahoo!, and Bing, you can use special search engines that are topical and help you search for niche information belonging to a specific category.
And use SG-Educate to jumpstart your search for the perfect SEO course. Our expert team curates complete courses and offers both online and in-person classes to help you succeed in your learning journey. Take advantage of our research support and comprehensive training today.
If you’re new to the field of SEO, this guide covers all aspects so you can gain a thorough understanding of the basics. Read on to learn about every element of SEO and get your bearings in the exciting world of online marketing.
Understand the Basics of SEO: Let’s maximize your site’s traffic today
Next Chapter >>
Thanks For Reading.
If you liked this article and want to read more of it, please subscribe to our newsletter and follow us on Facebook, Youtube, Linkedin, and Twitter.

Hamza Khan is an SEO specialist & Content writer with over 3 years of experience in the field. With a passion for helping businesses improve their online presence, Hamza has a track record of delivering successful SEO campaigns for a wide range of clients. He is skilled in keyword research, on-page optimization, and technical SEO, Off-Page and is always up-to-date with the latest trends and best practices in the industry.













